自然语言处理技术在过去几年中已经变得相当复杂. 从科技巨头到业余爱好者, 许多人都急于构建可以进行分析的富界面, 理解, 并对自然语言做出反应. 亚马逊的Alexa, 微软的Cortana, 谷歌的谷歌主页, 苹果的Siri都旨在改变我们与电脑互动的方式.
情绪分析, 自然语言处理的一个子领域, 由决定文本或讲话语气的技巧组成. Today, 通过机器学习和从社交媒体和评论网站收集的大量数据, 我们可以训练模型来相当准确地识别自然语言段落的情感.
在本教程中, 您将学习如何构建一个机器人,它可以分析它收到的电子邮件的情绪,并通知您可能需要立即注意的电子邮件.
该bot将使用Java和 Python开发. 这两个进程将使用Thrift相互通信. 如果您不熟悉其中一种或两种语言, 您仍然可以继续阅读,因为本文的基本概念也适用于其他语言.
判断一封邮件是否需要你的关注, 机器人将解析它并确定是否有强烈的负面语气. 然后,如果需要,它将发送文本警报.
我们将使用Sendgrid连接到我们的邮箱,使用Twilio发送文本警报.
有些词和积极的情绪联系在一起,比如爱、快乐和快乐. 还有一些词和负面情绪联系在一起,比如仇恨、悲伤和痛苦. 为什么不训练模型来识别这些单词,并计算每个积极和消极单词的相对频率和强度呢?
好吧,这有几个问题.
首先,有一个否定的问题. 例如, 像“桃子还不错”这样的句子,用一个我们通常与消极联系在一起的词,暗示了一种积极的情绪. 一个简单的词袋模型将无法识别这句话中的否定.
此外,混合情绪被证明是幼稚情绪分析的另一个问题. 例如, 像“桃子还不错。, 但是苹果真的很糟糕”这句话包含了相互影响的复杂情绪. 一个简单的方法将无法解决共同的情绪, 不同的强度, 或者情感之间的相互作用.
The 斯坦福自然语言处理 情感分析库使用递归神经张量网络(RNTN)解决了这些问题。.
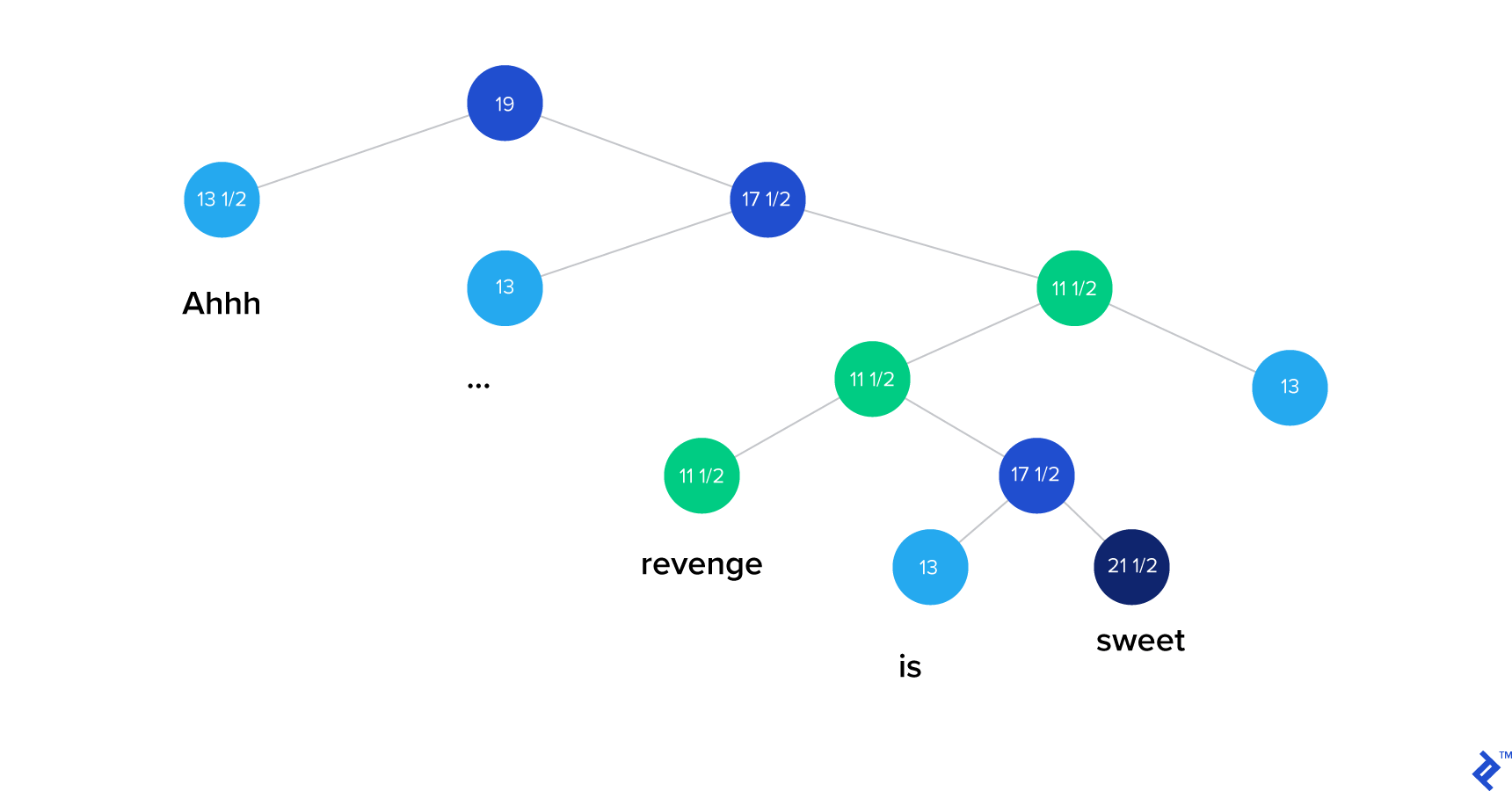
RNTN算法首先将一个句子分成单独的单词. 然后,它构建一个神经网络,其中节点是单个单词. Finally, 添加了一个张量层,以便模型可以适当地调整单词和短语之间的相互作用.
你可以在他们的网站上找到这个算法的可视化演示 官方网站.
斯坦福NLP小组使用手动标记的IMDB电影评论训练递归神经张量网络,并发现他们的模型能够非常准确地预测情绪.
您要做的第一件事是设置电子邮件集成,以便数据可以通过管道传输到您的机器人.
有很多方法可以做到这一点, 但是为了简单起见, 让我们设置一个简单的web服务器,并使用Sendgrid的入站解析钩子将电子邮件传输到服务器. 我们可以将电子邮件转发到Sendgrid的入站解析地址. 然后,Sendgrid将向我们的web服务器发送一个POST请求, 然后我们就可以通过我们的服务器处理这些数据.
为了构建服务器,我们将使用Flask,一个简单的web框架 Python.
除了构建web服务器之外,我们还需要将web服务连接到域. 为简洁起见,我们将在本文中跳过这部分内容. 然而,你可以阅读更多关于它的内容 here.
构建web服务器 Flask 非常简单.
只需创建一个 app.py 并将此添加到文件中:
从flask中导入flask
进口日期时间
app = Flask(__name__)
@app.路线(/分析,方法=['文章'])
def分析():
与开放(的日志文件.Txt ', 'a')作为fp_log:
fp_log.写入('端点命中%s \n' %日期时间.datetime.now().strftime(“% Y - % m - H % d %: % m: % S '))
返回“get it”
app.(主机运行= ' 0.0.0.0')
如果我们将这个应用程序部署在域名后面,并点击“/analyze”端点, 你应该看到这样的内容:
> >> requests.文章(http://sentiments.shanglunwang.com: 5000 /分析”).text
'Got it'
接下来,我们要向这个端点发送电子邮件.
您可以找到更多文档 here 但你基本上想设置Sendgrid作为你的电子邮件处理器,并让Sendgrid将电子邮件转发到我们的web服务器.
这是我在Sendgrid上的设置. 这将转发电子邮件到 @sentibot.shanglunwang.com POST请求到“http://sentiments”.shanglunwang.com/analyze”:
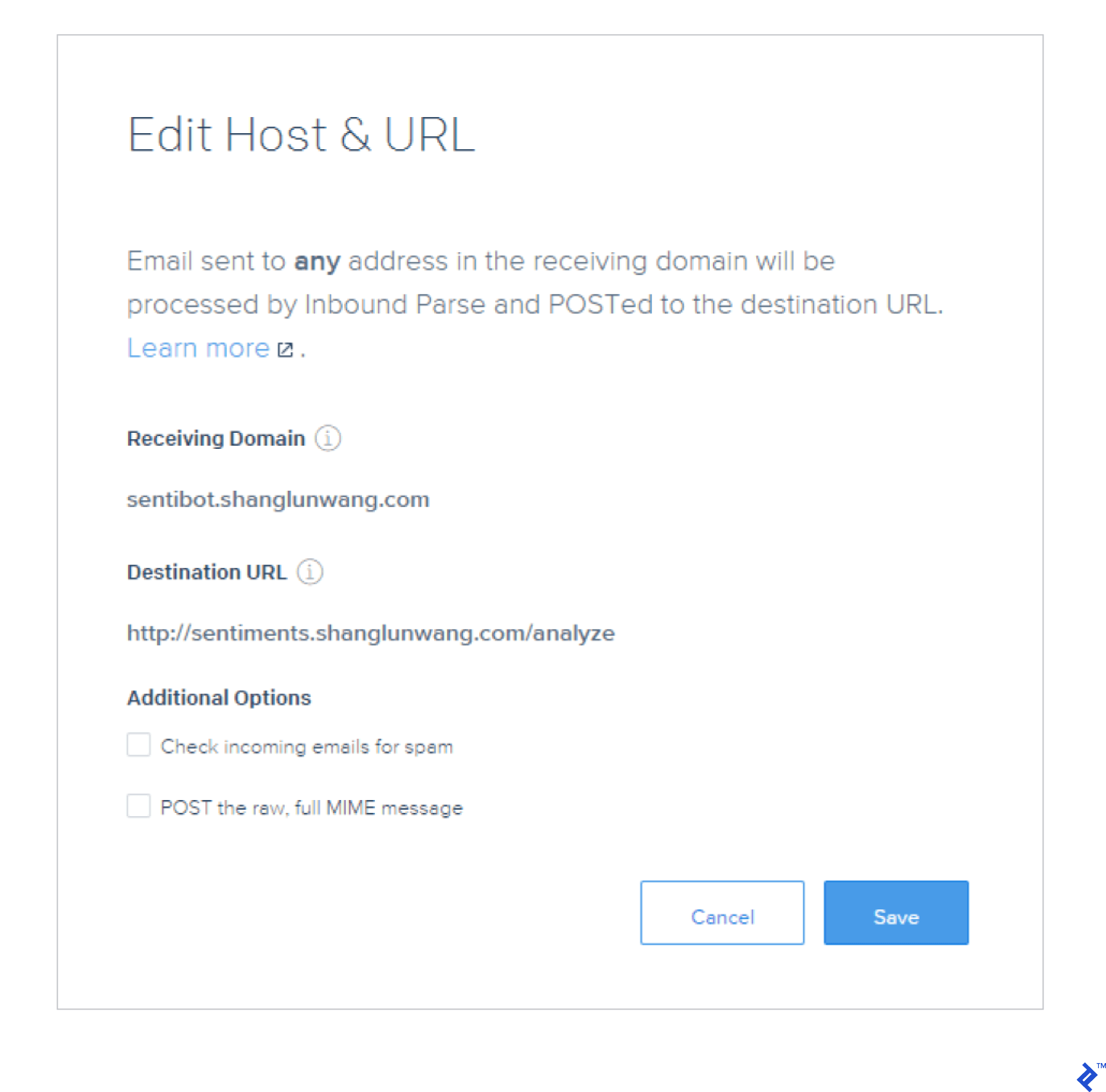
您可以使用任何其他支持通过webhook发送入站电子邮件的服务.
在设置好一切之后, 尝试发送电子邮件到您的Sendgrid地址, 你应该在日志中看到这样的内容:
终端命中2017-05-25 14:35:46
那太好了! 现在您有了一个能够接收电子邮件的机器人. 这是我们正在努力做的一半.
现在,你想给这个机器人分析电子邮件情绪的能力.
由于斯坦福NLP库是用Java编写的,所以我们希望用Java构建分析引擎.
让我们从下载斯坦福NLP库和Maven中的模型开始. 新建一个 Java 项目,将以下内容添加到Maven依赖项中,并导入:
edu.stanford.nlp
stanford-corenlp
3.6.0
斯坦福NLP的情感分析引擎可以通过在管道初始化代码中指定情感注释器来访问. 然后可以将注释作为树结构检索.
为本教程的目的, 我们只想知道一个句子的大意, 所以我们不需要解析整个树. 我们只需要看看基本节点.
这使得主代码相对简单:
包seanwang;
进口edu.stanford.nlp.pipeline.*;
进口edu.stanford.nlp.util.CoreMap;
进口edu.stanford.nlp.ling.CoreAnnotations;
进口edu.stanford.nlp.sentiment.SentimentCoreAnnotations;
导入java.util.*;
公共类App
{
public static void main(String[] args)
{
属性pipelineProps =新属性();
Properties tokenizerProps = new Properties();
pipelineProps.setProperty("annotators", "parse, sentiment");
pipelineProps.setProperty(“解析.binaryTrees”、“真正的”);
pipelineProps.setProperty(“enforceRequirements”,“假”);
tokenizerProps.setProperty("annotators", "tokenize ssplit");
standfordcorenlp tokenizer = new standfordcorenlp (tokenizerProps);
StanfordCoreNLP管道= new StanfordCoreNLP(pipelineProps);
非常感激的漂亮朋友们正在完成一件非常快乐的事. 这真是一个可怕的主意.";
Annotation =标记器.过程(线);
pipeline.注释(annotation);
//正常输出
对于CoreMap句子:注释.get (CoreAnnotations.SentencesAnnotation.class)) {
字符串输出=句子.get (SentimentCoreAnnotations.SentimentClass.class);
System.out.println(输出);
}
}
}
尝试一些句子,您应该会看到适当的注释. 运行示例代码输出:
非常积极的
Negative
所以我们有一个用Java编写的情感分析程序和一个用Python编写的电子邮件机器人. 我们怎么让他们互相交谈?
这个问题有许多可能的解决方案,但在这里我们将使用 Thrift. 我们将启动情绪分析器作为一个Thrift服务器和电子邮件机器人作为一个Thrift客户端.
Thrift是一个代码生成器和一个协议,用于启用两个应用程序, 通常用不同的语言写的, 能够使用已定义的协议相互通信. 多语言团队使用Thrift构建微服务网络,以充分利用他们使用的每种语言的优点.
要使用Thrift,我们需要两样东西:a .thrift 文件中定义的服务端点,并生成代码以使用在 .proto file. 对于分析器服务, sentiment.thrift 看起来像这样:
命名空间Java情绪
Namespace py情绪
服务SentimentAnalysisService
{
字符串情感分析(1:字符串句子),
}
我们可以使用它生成客户端和服务器代码 .节俭的文件. Run:
thrift-0.10.0.Exe——gen py情绪.thrift
thrift-0.10.0.Exe——gen Java情绪.thrift
注意:我是在Windows机器上生成代码的. 您将希望在您的环境中使用到Thrift可执行文件的适当路径.
现在,让我们对分析引擎进行适当的更改以创建服务器. 你的Java程序应该是这样的:
SentimentHandler.java
包seanwang;
公共类sentimentandler实现SentimentAnalysisService.Iface {
SentimentAnalyzer分析仪;
SentimentHandler () {
analyzer = new SentimentAnalyzer();
}
公共字符串sentimentAnalyze(字符串句子){
System.out.Println ("got: " +句子);
返回分析仪.分析(句子);
}
}
这个处理程序是我们通过Thrift协议接收分析请求的地方.
SentimentAnalyzer.java
包seanwang;
// ...
公共类SentimentAnalyzer {
StanfordCoreNLP记号赋予器;
StanfordCoreNLP管道;
公共SentimentAnalyzer() {
属性pipelineProps =新属性();
Properties tokenizerProps = new Properties();
pipelineProps.setProperty("annotators", "parse, sentiment");
pipelineProps.setProperty(“解析.binaryTrees”、“真正的”);
pipelineProps.setProperty(“enforceRequirements”,“假”);
tokenizerProps.setProperty("annotators", "tokenize ssplit");
tokenizer = new StanfordCoreNLP(tokenizerProps);
pipeline = new StanfordCoreNLP(pipelineProps);
}
公共字符串分析(字符串行){
Annotation =标记器.过程(线);
pipeline.注释(annotation);
字符串输出= "";
对于CoreMap句子:注释.get (CoreAnnotations.SentencesAnnotation.class)) {
输出+=句子.get (SentimentCoreAnnotations.SentimentClass.class);
输出+= "\n";
}
返回输出;
}
}
Analyzer使用Stanford NLP库来确定文本的情感,并为文本中的每个句子生成一个包含情感注释的字符串.
SentimentServer.java
包seanwang;
// ...
公共类SentimentServer {
公共静态SentimentHandler处理程序;
公共静态SentimentAnalysisService.处理器处理器;
public static void main(String [] args) {
try {
handler = new SentimentHandler();
processor = new SentimentAnalysisService.处理器(处理器);
Runnable simple = new Runnable() {
公共无效运行(){
简单(处理器);
}
};
新线程(简单的).start();
} catch(异常x) {
x.printStackTrace ();
}
}
(SentimentAnalysisService ..处理器处理器){
try {
TServerTransport = new TServerSocket(9090);
TServer server = new TSimpleServer(new Args(serverTransport)).处理器(处理器));
System.out.启动简单服务器...");
server.serve();
} catch(异常e) {
e.printStackTrace ();
}
}
}
注意,我没有包括 SentimentAnalysisService.java 文件,因为它是生成的文件. 您将希望将生成的代码放在其他代码可以访问的地方.
现在我们已经建立了服务器,让我们编写一个Python客户机来使用服务器.
client.py
从情感导入SentimentAnalysisService
从节俭.传输导入TSocket
从节俭.运输进口
从节俭.导入TBinaryProtocol
类SentimentClient:
Def __init__(self, server='localhost', socket=9090):
transport = TSocket.TSocket(服务器套接字)
运输=运输.TBufferedTransport(运输)
protocol = TBinaryProtocol.TBinaryProtocol(运输)
self.运输
self.client = SentimentAnalysisService.客户端(协议)
self.transport.open()
def __del__(自我):
self.transport.close()
解析(self,句子):
回归自我.client.sentimentAnalyze(句子)
如果__name__ == '__main__':
client = SentimentClient ()
打印(客户端.分析(“一个奇妙的句子”))
运行这个,你应该看到:
非常积极的
Great! 现在我们已经运行了服务器并与客户机进行了通信, 让我们通过实例化一个客户端并将电子邮件导入其中来将其与电子邮件机器人集成.
导入客户端
# ...
@app.路线(/分析,方法=['文章'])
def分析():
Sentiment_client = client.SentimentClient ()
与开放(的日志文件.Txt ', 'a')作为fp_log:
fp_log.写(str(请求.form.('文本')))
fp_log.写(请求.form.('文本'))
fp_log.写(sentiment_client.分析(请求.form.('文本')))
返回“get it”
现在将Java服务部署到运行web服务器的同一台机器上, 启动服务, 然后重启应用程序. 向机器人发送一封带有测试句子的电子邮件,您应该在日志文件中看到如下内容:
非常积极和美丽的句子.
非常积极的
All right! 现在我们有了一个能够进行情感分析的电子邮件机器人! 我们可以发送电子邮件,并收到我们发送的每个句子的情感标签. 现在,让我们来探讨一下如何使情报具有可操作性.
为了让事情简单化, 让我们把重点放在那些高度集中了否定句和非常否定句的电子邮件上. 让我们使用一个简单的评分系统,假设一封电子邮件包含超过75%的负面情绪句子, 我们会将其标记为可能需要立即回复的潜在警报邮件. 让我们在analyze路由中实现评分逻辑:
@app.路线(/分析,方法=['文章'])
def分析():
Text = str(请求.form.('文本'))
Sentiment_client = client.SentimentClient ()
text.Replace ('\n', ") #删除所有新行
句子=文本.rstrip('.').split('.’)#删除分裂前的最后一段
negative_sentence = [
句接句,句接句
如果sentiment_client.分析(句子).rstrip() in ['Negative', 'Very Negative'] # remove换行字符
]
urgent = len(negative_sentences) / len(sentences) > 0.75
与开放(的日志文件.Txt ', 'a')作为fp_log:
fp_log.写("已收到:%s") %(请求.form.('文本')))
fp_log.Write ("urgent = %s" % (str(urgent)))
返回“get it”
上面的代码做了一些假设,但用于演示目的. 发送几封电子邮件到你的机器人,你应该在日志中看到电子邮件分析:
收到:这是对系统的测试. 这应该是一个非紧急请求.
非常好! 在大多数情况下,这是积极的或中性的. 伟大的事情
正在发生!
紧急=假
收到:这是一个紧急请求. 一切都很糟糕. 这是一场灾难.
人们讨厌这种无味的邮件.
紧急=真
我们快做完了!
我们已经建立了一个电子邮件机器人,能够接收电子邮件, 进行情绪分析, 确定一封邮件是否需要立即处理. 现在,当收到一封特别负面的邮件时,我们只需要发送短信提醒.
我们将使用Twilio发送文本警报. 他们的Python API,有文档记录 here很简单. 让我们修改分析路由,以便在接收到紧急请求时发出请求.
def send_message(身体):
twilio_client.messages.create(
= on_call,
from_=os.采用“TWILIO_PHONE_NUMBER”),
body=body
)
app = Flask(__name__)
@app.路线(/分析,方法=['文章'])
def分析():
Text = str(请求.form.('文本'))
Sentiment_client = client.SentimentClient ()
text.Replace ('\n', ") #删除所有新行
句子=文本.rstrip('.').split('.’)#删除分裂前的最后一段
negative_sentence = [
句接句,句接句
如果sentiment_client.分析(句子).rstrip() in ['Negative', 'Very Negative'] # remove换行字符
]
urgent = len(negative_sentences) / len(sentences) > 0.75
如果紧急:
收到了非常负面的邮件. 请采取行动!”
与开放(的日志文件.Txt ', 'a')作为fp_log:
fp_log.写("已收到:" %请求.form.('文本'))
fp_log.Write ("urgent = %s" % (str(urgent)))
fp_log.写(“\ n”)
返回“get it”
您需要将您的环境变量设置为您的Twilio帐户凭据,并将呼叫号码设置为您可以检查的电话. 一旦你做到了, 向分析端点发送一封电子邮件,您应该会看到一个文本被发送到有问题的电话号码.
完成了!
在本文中, 您学习了如何使用斯坦福NLP库构建电子邮件情感分析机器人. 该库有助于抽象出自然语言处理的所有细节,并允许您将其用作NLP应用程序的构建块.
我希望这篇文章展示了情感分析的许多惊人的潜在应用之一, 这会激励你建立一个自己的NLP应用程序.
你可以在NLP教程中找到邮件情感分析机器人的代码 GitHub.
自然语言处理是使用算法来分析和理解普通的人类语言,以确定诸如情绪之类的指标.
Stanford NLP库是一组用Java编写的自然语言处理软件,由Stanford NLP Group构建并开放源代码.
递归神经张量网络是一组以树状结构组织的神经网络,其中每个节点都是一个神经网络. 这在自然语言处理中特别有用,在自然语言处理中,算法处理单词及其在句子中的相互作用.
Sean是一个充满激情的通晓多种语言的人:一个全栈向导、系统管理员和数据科学家. 他还开发了市场情报软件.
 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
世界级的文章,每周发一次.
世界级的文章,每周发一次.

