
费德里科•阿尔巴内塞
验证专家 in 工程
Federico是一名开发人员和数据科学家,曾在脸谱网工作, 他在哪里做了机器学习模型预测. 他是Python专家和大学讲师. 他的博士研究方向是图形机器学习.
以前在

Federico是一名开发人员和数据科学家,曾在脸谱网工作, 他在哪里做了机器学习模型预测. 他是Python专家和大学讲师. 他的博士研究方向是图形机器学习.
计算机和为其提供动力的处理器是用来处理数字的. 与此形成鲜明对比的是, 电子邮件和社交媒体帖子的日常语言结构松散,不适合计算.
这就是 自然语言处理 (NLP)出现了. NLP是计算机科学的一个分支,通过应用计算技术(即人工智能)来分析自然语言和语音,与语言学重叠. 主题建模的重点是理解给定文本是关于哪些主题的. 主题建模可以让开发人员实现有用的功能,比如检测社交媒体上的突发新闻, 推荐个性化信息, 检测假用户, 以及信息流的特征.
开发人员如何才能让专注于计算的计算机理解那些复杂程度的人类交流?
要回答这个问题,我们需要能够用数学方法描述一篇文章. 我们将开始主题建模 Python 教程用最简单的方法:包字.
此方法将文本表示为一组单词. 例如,这个句子 这是一个例子 可以用这些词出现的频率来描述为一组词:
{"an": 1, "example": 1, "is": 1, "this": 1}
注意这个方法忽略了词序. 举几个例子:
这两种情绪用同样的词语来表达,但它们的意思相反. 然而,为了分析文本的主题,这些差异并不重要. 这两种情况, 我们谈论的是哈利波特和星球大战的口味, 不管这些口味是什么. 因此,词序并不重要.
当我们有多个文本并试图理解它们之间的差异时, 我们需要为整个语料库分别考虑每个文本的数学表示. 我们可以用矩阵, 其中,每一列代表一个单词或术语,每行代表一个文本. 语料库的一种可能的表示方式是在每个单元格中记录给定单词(列)在特定文本(行)中的使用频率。.
在我们的示例中,语料库由两个句子(我们的矩阵行)组成:
“我喜欢哈利波特。”
我喜欢《欧博体育app下载》
我们按照遇到单词的顺序列出语料库中的单词: I, 就像, 哈利, 波特, 明星, 战争. 这些对应于我们的矩阵列.
矩阵中的值表示给定单词在每个短语中使用的次数:
[[1,1,1,1,0,0],
[1,1,0,0,1,1]]

请注意,矩阵的大小是通过将文本数乘以至少一个文本中出现的不同单词数来确定的. 后者通常是不必要的大,可以减少. 例如, 矩阵可能包含两列表示共轭动词, 比如“play”和“played”,,而不管它们的意思是相似的.
但描述新概念的专栏可能会缺失. 例如, “古典”和“音乐”各有各自的含义,但当它们结合在一起时——“古典音乐”——它们就有了另一个含义.
由于这些问题,有必要对文本进行预处理,以获得良好的效果.
为了获得最佳效果,有必要使用多种预处理技术. 下面是一些最常用的:
Tf-idf是衡量一个词在语料库中使用频率的指标. 能够将单词细分成组, 重要的是不仅要了解每个文本中出现了哪些单词, 还有哪些词在一篇文章中频繁出现,而在其他文章中却完全不出现.
下图显示了其中的一些简单示例 预处理技术 语料库的原始文本在哪里被修改,以生成相关的和可管理的单词列表.
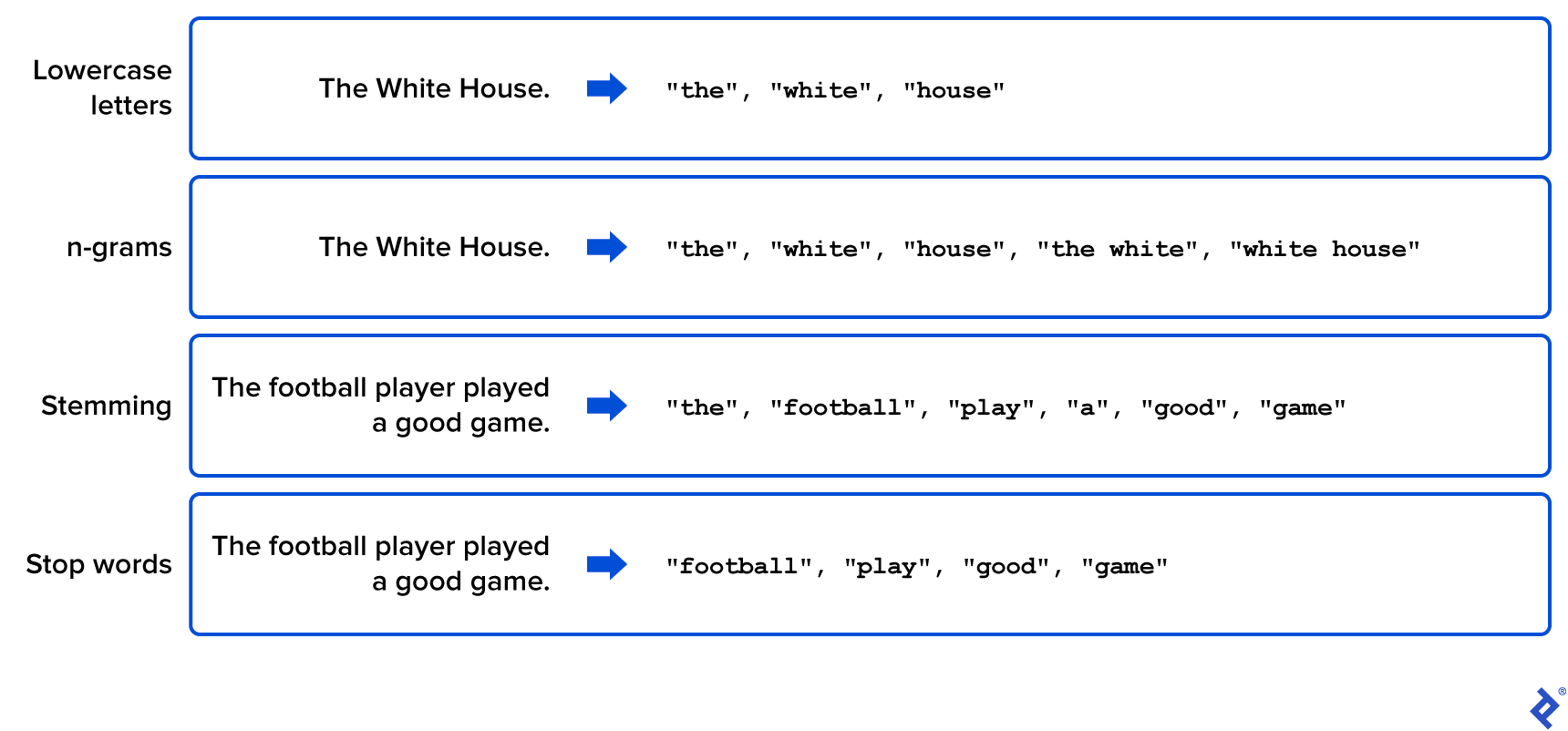
现在我们将演示如何在Python中应用这些技术. 一旦我们把语料库用数学表示出来, 我们需要通过应用无监督机器学习算法来识别正在讨论的主题. 在这种情况下, “无监督”意味着该算法没有任何预定义的主题标签, 比如“科幻小说”,来应用于它的输出.
聚类语料库, 我们可以从几种算法中进行选择, 包括非负矩阵分解(NMF), 稀疏主成分分析, 潜狄利克雷分配(LDA). 我们将重点介绍LDA,因为它在社交媒体上取得了良好的效果,被科学界广泛使用, 医学科学, 政治科学, 软件工程.
LDA是一种无监督主题分解模型:它根据文本包含的单词和某个单词属于某个主题的概率对文本进行分组. LDA算法输出主题词分布. 有了这些信息, 我们可以根据最可能与主题相关的单词来定义主题. 一旦我们确定了主要主题和与之相关的单词, 我们可以知道哪个或哪个主题适用于每个文本.
考虑以下由五个短句组成的语料库(全部取自 纽约时报 标题):
拉斐尔·费德勒(Rafael b纳达尔)和费德勒(Roger Federer)一起思念美国.S. 开放”,
“拉斐尔退出澳网”,
"拜登宣布应对病毒措施"
“拜登的病毒计划面临现实”,
“拜登的病毒计划在哪里?”
该算法应该明确识别一个与政治和冠状病毒相关的主题, 第二个与纳达尔和网球有关.
为了检测主题,我们必须导入必要的库. Python有一些用于NLP和机器学习的有用库,包括 NLTK 和 Scikit-learn (sklearn).
从sklearn.feature_extraction.文本导入CountVectorizer
从sklearn.feature_extraction.文本导入TfidfTransformer
从sklearn.分解导入LatentDirichletAllocation作为LDA
从nltk.语料库导入停词
使用 CountVectorizer (),我们生成矩阵,表示每个文本中使用的单词的频率 CountVectorizer (). 请注意,如果您包含诸如 stop_words 为了包含停顿词, ngram_range 包括 n克,或 小写= True 将所有字符转换为小写.
count_vect = count_ectorizer (stop_words=stopwords.词(英语)、小写= True)
X_counts = count_vect.fit_transform(主体)
x_counts.todense ()
矩阵([[0,0,0,1,1,0,0,1,1,- 1,0,0,1,0,1,0,0),
[0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0],
[1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1],
(0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1]], dtype = int64)
要定义语料库的词汇表,我们可以简单地使用属性 .get_feature_names ():
count_vect.get_feature_names ()
(“宣布”, “澳大利亚”, 拜登的, 费德勒的, “连接”, “措施”, “满足”, “失踪”, “纳达尔”, “开放”, “计划”, “计划”, “拉斐尔。”, “现实”, “罗杰”, “站”, “病毒”)
然后,我们使用sklearn函数执行tf-idf计算:
tfidf_transformer = TfidfTransformer()
X_tfidf = tfidf_transformer.fit_transform (x_counts)
为了执行LDA分解,我们必须定义主题的数量. 在这个简单的例子中,我们知道有两个主题或“维度”.“但在一般情况下,这是一个超参数 需要一些调整,这可以使用随机搜索或网格搜索等算法来完成:
尺寸= 2
lda = lda (n_components = dimension)
Lda_array = lda.fit_transform (x_tfidf)
lda_array
数组([[0.8516198 , 0.1483802 ],
[0.82359501, 0.17640499],
[0.18072751, 0.81927249],
[0.1695452 , 0.8304548 ],
[0.18072805, 0.81927195]])
LDA是一种概率方法. 在这里,我们可以看到五个标题分别属于两个主题的概率. 我们可以看到,前两篇文章更有可能属于第一个主题,后三篇文章更有可能属于第二个主题, 正如预期的.
最后, 如果我们想了解这两个主题是关于什么的, 我们可以看到每个主题中最重要的单词:
组件= [lda ..Components_ [i] for i in range(len(lda).components_)))
特征= count_vect.get_feature_names ()
Important_words = [sorted(features), key = lambda x: components[j][features ..index(x), reverse = True)[:3] for j in range(len(components))]
important_words
[[“开放”, '纳达尔',“拉斐尔。”],
['virus', 拜登的, “措施”]]
正如预期的, LDA正确地将与网球锦标赛和纳达尔相关的单词分配到第一个主题,将与拜登和病毒相关的单词分配到第二个主题.
从中可以看出对主题建模的大规模分析 纸; I studied the main news topics during the 2016 US presidential election 和 observed the topics some mass media—就像 the 纽约时报 和福克斯新闻——包括在他们的报道中,比如腐败和移民. 在本文中, 我还分析了大众媒体内容与选举结果之间的相关性和因果关系.
主题建模在学术界之外也被广泛用于发现存在于大量文本集合中的隐藏主题模式. 例如, 它可以用于推荐系统或在调查中确定客户/用户在谈论什么, 在反馈形式中, 或者在社交媒体上.
Toptal 工程博客向 胡安·曼纽尔·奥尔蒂斯·德·萨拉特 查看本文中提供的代码示例.
改进了Twitter的主题建模
艾博年,费德里科和埃斯特班·费尔斯坦. “通过社区池改进Twitter的主题建模.(2021年12月20日): arXiv: 2201.00690 [cs.IR]
为公共卫生分析Twitter
保罗,迈克尔和马克·德雷兹. “你就是你的推特:为公共卫生分析推特.2021年8月3日.
在推特上分类政治倾向
科恩,拉维夫和德里克·鲁斯. “分类推特上的政治倾向:这并不容易!2021年8月3日.
使用关系主题模型捕获耦合
格瑟斯,马尔科姆和丹尼斯·波希瓦尼克. “用关系主题模型捕捉面向对象软件系统中类之间的耦合.2010年10月25日.
主题建模使用统计和机器学习模型来自动检测文本文档中的主题.
主题建模用于不同的任务, 比如在社交媒体上发现趋势和新闻, 检测假用户, 个性化消息推荐, 以及信息流的特征.
有多种监督和非监督主题建模技术. 有些使用标记文档数据集对文章进行分类. 其他人则分析单词出现的频率,以推断语料库中的潜在主题.
不,它们不一样. 文本分类是一种监督学习任务,它将文本分类到预定义的组中. 相反,主题建模不一定需要标记数据集.
世界级的文章,每周发一次.
世界级的文章,每周发一次.

 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.